Vào cuối năm 2015, các chuyên gia hàng đầu trong lĩnh vực SEO đã thực hiện một thử nghiệm với mong muốn dự đoán xếp hạng Google với một trang web cho sẵn có sử dụng Machine Learning. Dưới đây, DỊCH VỤ SEO NẮNG XANH tóm lược những kết quả tìm kiếm của họ, những điều họ muốn chia sẻ với cộng đồng SEO.
Machine Learning hiện nay nhanh chóng trở thàn một công cụ không thể thiếu với nhiều công ty lớn. Có lẽ đa số mọi người đều từng nghe về thuật toán của Google từng chiến thắng trong cuộc thi World Champion in Go, cũng như là với các công nghệ như là RankBrain. Nhưng Machine Learning không phải là một chủ đề thần bí chỉ liên quan đến các nghiên cứu về toán học. Có rất nhiều nguồn tư liệu và công nghệ có thể tiếp cận được mà cho thấy sự hứa hẹn một vai trò rất hữu ích của Machine Learning trong bất kỳ lĩnh vực nào.
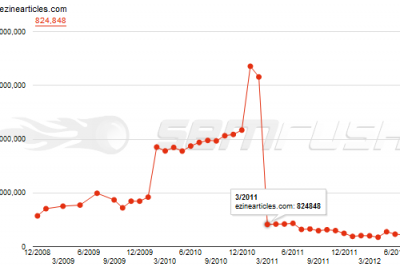
Machine Learning còn có khả năng biến SEO và website marketing truyền thống trở nên cải tiến hơn. Vào cuối năm ngoái, những chuyên gia SEO hàng đầu đã bắt đầu một cuộc thử nghiệm bỏ qua một số thuật toán Machine Learning phổ biến nhằm dự đoán thứ hạng trong Google. Họ đã kết thúc với việc đạt được con số 41% thực sự tích cực và 41% thực sự tiêu cực trong nguồn dữ liệu.
Trong phần dưới đây, DỊCH VỤ SEO NẮNG XANH muốn trình bày những điều các chuyên gia SEO đã thực hiện, và bàn luận về một số dữ liệu cần thiết và công nghệ có quan trọng với SEOer.
Vào cuối năm 2015, chúng ta bắt đầu được nghe nhiều hơn về Machine Learning và sự hứa hẹn của nó trong việc tạo hiệu quả cho phần lớn dữ liệu. Chúng ta càng đào sâu, thì càng phát hiện những chi tiết kỹ thuật, và nó nhanh chóng trở nên rõ ràng là nó sẽ hữu ích trong việc giúp cúng ta định hướng lĩnh vực này.
Vào khoảng thời gian này, họ đã tìm hiểu về nguồn dữ liệu khoa học phong phú từ Alejandro Simkievich. Điều thú vị mà họ được biết là Simkievich đã làm việc trong lĩnh vực những điều có liên quan đến tìm kiếm và tối ưu hóa tỉ lệ chuyển đổi, và cuộc thi Kaggle. Kaggle là một website tổ chức các cuộc thi về Machine Learning cho nhóm các nhà khoa học và người đam mê Machine Learning.
Simkievich là chủ sở hữu của Statec, một công ty tư vấn khoa học dữ liệu và Machine Learning, với những khách hàng lớn trong lĩnh vực hàng tiêu dùng, tự động, marketing, internet. Có rất nhiều việc Statec là tập trung vào mảng đánh giá sự liên quan của công cụ tìm kiếm thương mại điện tử. Và việc họ hợp tác với nhau là sự phối hợp tự nhiên, kể từ khi họ sử dụng dữ liệu để giúp khách hàng ra quyết định trong SEO.
Họ muốn thiết lập mục tiêu lớn, vì vậy họ quyết định xem liệu có thể sử dụng dữ liệu có sẵn từ scraping, rank tracker, công cụ link và một số công cụ khác để xem liệu họ có thể tạo nên các tính năng sẽ cho phép họ dự đoán xếp hạng của một trang web.
Về cơ bản, Machine Learning sử dụng các chương trình máy tính để lấy dữ liệu và chuyển đổi nó theo cách mà mang lại thông tin có giá trị. Chuyển đổi là một từ có ứng dụng rất lỏng lẻo, trong đó nó không hoàn toàn công bằng với tất cả những thứ có liên quam. Nhưng nó thực sự được lựa chọn để làm mẫu cho dễ hiểu. Vấn đề ở đây là tất cả Machine Learning đều bắt đầu với một số dữ liệu đầu vào.
Điểm mấu chốt là ho phải tìm các dữ liệu mà có thể sử dụng để hướng dẫn cho mô hình Machine Learning. Về điểm này, họ không biết chính xác là điều gì sẽ hữu ích, cho nên họ sử dụng một phương pháp tiếp cận nắm lấy nhiều thông tin mà họ có thể nghĩ đến. GetStart và Majestic từng là vô giá trong việc cung cấp rất nhiều dữ liệu cơ bản. Và họ đã xây dựng một trình thu nhập để nắm bắt tất cả mọi thứ.
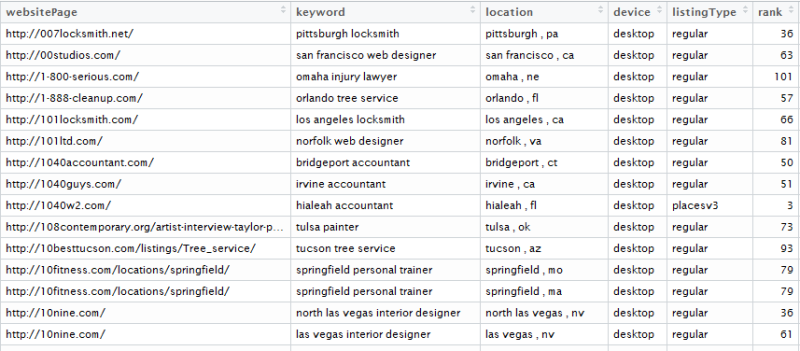
Mục tiêu của họ là hoàn tất với dữ liệu để hướng dẫn một model thành công, điều này cũng có nghĩa là có nhiều dữ liệu. Đối với model đầu tiên, họ đã có khoảng 200.000 lượt quan sát ( theo hàng), và 54 thuộc tính (cột). Một chút cơ bản
Như Thiết kế web chuẩn SEO từng đề cập, là sẽ không đi quá chi tiết về Machine Learning. Nhưng cũng khá quan trọng để nắm bắt một số điểm chính để hiểu được phần tiếp theo. Tổng quan, đa số các Machine Learning làm việc lý tưởng với các thuật toán hồi quy, phân loại và phân nhóm.
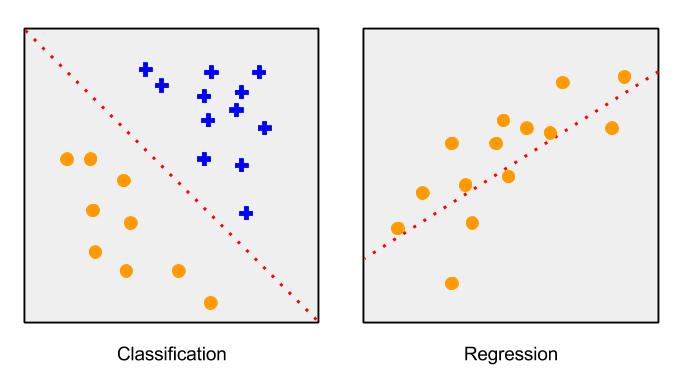
Thuật toán hồi quy thường hữu ích để dự đoán một số duy nhất. Nếu bạn cần tạo ra một thuật toán dự đoán giá cổ phiếu dựa trên các tính năng của cổ phiếu, bạn sẽ chọn loại mô hình này. Chúng được gọi là các biến liên tục. Phân loại các thuật toán được sử dụng để dự đoán một thành viên của một loạt các câu trả lời có thể. Đây có thể là phân loại đơn giản "có hoặc không", hoặc "màu đỏ, xanh lá cây hoặc màu xanh." Nếu bạn cần dự đoán liệu một người chưa biết là nam hay nữ từ tính năng, bạn sẽ chọn loại mô hình. Chúng được gọi là các biến rời rạc.
Machine Learning là một không gian thiên về kỹ thuật, và nhiều công việc tiên tiến đòi hỏi sự quen thuộc với đại số tuyến tính, giải tích, ký hiệu toán học và ngôn ngữ lập trình như Python. Một trong những item đó đã giúp họ hiểu được dòng chảy tổng thể ở mức độ tiếp cận, mặc dù, là suy nghĩ của các mô hình Machine Learning như áp dụng trọng vào các tính năng trong các dữ liệu bạn cung cấp cho nó. Các tính năng càng quan trọng, thì trọng lượng càng mạnh mẽ hơn.
Khi bạn đọc về "mô hình đào tạo", nó là hữu ích để hình dung một chuỗi kết nối thông qua các mô hình cho mỗi trọng lượng, và là mô hình làm dự đoán, một hàm chi phí được sử dụng để cho bạn biết phán đoán đó đúng hay sai; nhẹ nhàng hoặc nghiêm khắc, kéo chuỗi theo hướng câu trả lời đúng, điều chỉnh tất cả các trọng số.
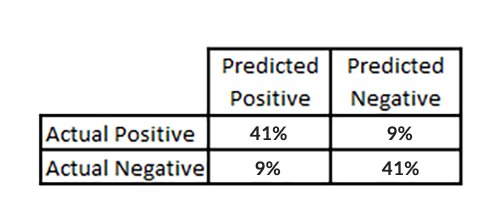
Các số liệu mà họ nghĩ rằng sẽ mang tính đại diện để đo lường hiệu quả của mô hình này lại là một ma trận metrix. Một ma trận metrix là một bảng thường dùng để mô tả hiệu suất của một mô hình phân loại trên một tập hợp các dữ liệu thí nghiệm mà các giá trị thực sự được biết đến.
Với 100 kết quả cho mỗi từ khóa, một sự phán đoán ngẫu nhiên sẽ dự đoán chính xác “ không phải top 1” chiếm 90% thời gian. Các ma trận metrix đảm bảo tính chính xác của cả các trả lời tích cực và tiêu cực. Họ thu được khoảng 41% câu trả lời thực sự tích cực và ngược lại trong cùng mô hình tốt nhất.
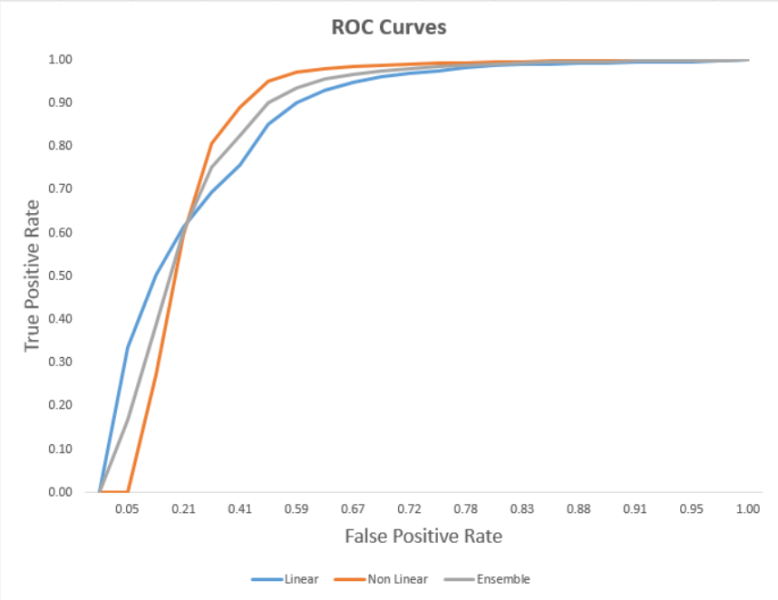
Một cách khác để hình dung hiệu quả của mô hình này là bằng cách sử dụng đường cong ROC. Đường cong ROC là "một đồ họa minh họa hiệu suất của một hệ thống phân loại nhị phân là ngưỡng phân biệt đối xử của nó là đa dạng. Các đường cong được tạo ra bằng cách vẽ các tỷ lệ dương tính thật (TPR) so với tỷ lệ dương tính giả (FPR) ở thiết lập ngưỡng khác nhau. Mô hình tuyến tính là logistic hồi quy.
Chúng ta là những nhà tiếp thị tìm kiếm, sống trong một thế giới của dữ liệu. Nên điều quan trọng là chúng ta hiểu công nghệ mới cho phép chúng ta đưa ra quyết định tốt hơn trong công việc. Machine Learning có thể giúp chúng ta hiểu, từ biết ý định của người sử dụng của chúng ta tốt hơn cho đến trang web nào mà hành động nào của website mang lại hành động.
Đối với những người quan tâm đến Machine Learning nhưng choáng ngợp với sự phức tạp của nó, DỊCH VỤ SEO NẮNG XANH muốn giới thiệu Data Science Dojo. Có hướng dẫn đơn giản sử dụng Machine Learning Studio của Microsoft mà rất gần gũi với người mới. Điều này cũng có nghĩa là bạn không phải học mã trước khi xây dựng mô hình đầu tiên của bạn.