Có nhiều lời đồn đoán xung quanh việc Google ra các hình phạt cho nội dung trùng lắp, nhưng chuyên gia Patrick Stox sẽ làm rõ vấn đề này. Một lần và mãi mãi. THIẾT KẾ WEBSITE CHUẨN SEO sẽ trình bày các giải thích của chuyên gia này.

Có nhiều lời đồn thổi xung quanh nội dung trùng lắp nên người ta nghĩ rằng nó gây ra hình phạt và vì đó mà các page của họ sẽ phải cạnh tranh với các page khac và tổn hại website của họ. Trên rất nhiều website tin tức về SEO, có nhiều bài viết về SEO cho thấy rằng người ta rõ ràng là không hiểu chính xác về cách mà Google xử phạt các nội dung bị trùng lắp.
Google đã cố gắng triệt tiêu các lời đồn thổi xung quanh vấn đề nội dung trùng lắp trong nhiều năm qua. Đã đến lúc chúng ta phải làm rõ vấn đề này.
“ Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin.”
Tạm dịch: “ Nội dung trùng lắp, về tổng quát là liên quan đến khối lượng nội dung bên trong hoặc trên domain mà giống toàn bộ như nội dung của một domain khác, hoặc là rất giống. Đa phần thì đây không phải là lừa đảo về mặt nguồn gốc”. Mọi người nhầm lẫn về nội dung trùng lắp chủ yếu là ở các hình phạt mà Google xử lý. Thực sự là các bản sao nội dụng chỉ được lọc trong các kết quả tìm kiếm. Bạn có thể thấy bằng cách thêm và lọc =0 vào cuối URL và loại bỏ các bộ lọc.
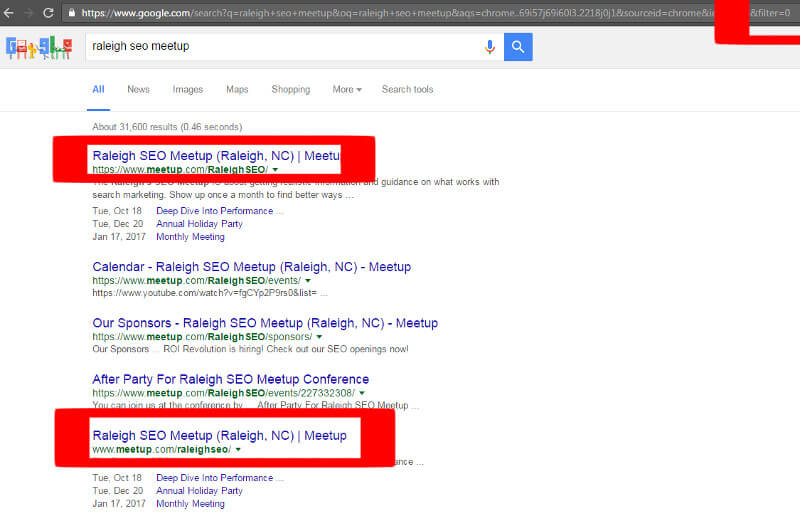
Ví dụ: thêm và lọc =0 vào cuối URL page cho một truy vấn “ raleigh seo meetup”, nó sẽ cho thấy một trang giống chính xác 2 lần. Ở đây không phải nói Meetup đã làm quá tốt, mà kể từ khi họ thực sự tạo ra 2 phiên bản HTTP và HTTPS- chỉ trong trường hợp này, thì cả 2 link đó đều chính xác trong việc sử dụng thẻ canonical. Nhưng thực ra, nó chỉ cho thấy trang giống chính xác đã thực sự được lập chỉ mục, và chỉ có kết quả liên quan nhất được đưa ra. Nó không phải là trang cạnh tranh hay là một trang gây tổn hại cho chính nó.
Theo như Matt Cutts, có khoảng 25-30 % của web bị trùng lặp nội dung. Một nghiên cứu gần nhất từ Raven Toold dựa trên dữ liệu từ các công cụ tìm thấy một kết quả tương tự: là 29% của các page có trùng lặp nội dung.
Có rất nhiều bài đăng được xuất bản bởi chính người nhà Google. Dưới đây là một bảng tóm tắt các nội dung tốt nhất liên quan đến chủ đề này.
Deftly dealing with duplicate content Duplicate content due to scrapers Google, duplicate content caused by URL parameters, and you Duplicate content summit at SMX Advanced Learn the impact of duplicate URLs Duplicate content (Search Console Help)
Các giải pháp này sẽ tùy thuộc vào các tình huống cụ thể:
Có một số điều mà thực sự có thể gây ra vấn đề, chẳng hạn như scraping / thư rác. Nhưng đối với hầu hết các phần, các vấn đề sẽ bị gây ra bởi chính các trang web. Không không cho phép trong robots.txt, không nofollow, không noindex, không canonical từ các trang mục tiêu đuôi dài. Nhưng hãy sử dụng các tín hiệu nói trên cho các vấn đề cụ thể của bạn để chỉ ra cách bạn muốn các nội dung được xử lý. Kiểm tra phần trợ giúp của Google về nội dung trùng lặp.
Các lời đồn đoán về trừng phạt nội dung trùng lặp cần phải chấm dứt. Audit, các công cụ và các sự hiểu lầm cần được chỉnh sửa bằng thông tin chính xác. Nếu không các đồn đoán này có thể tồn tại khoảng hơn 10 năm nữa. Có rất nhiều cách để củng cố tín hiệu trên nhiều trang, và thậm chí nếu bạn không sử dụng chúng, Google sẽ cố gắng củng cố các tín hiệu cho bạn.









