Lọc 1 trang sách rất dễ nhưng với hàng tỷ trang web thì nó lọc và sắp xếp nó sẽ là khối lượng công việc khổng lồ. Google giải quyết bài toán này qua thư viện từ vựng, xây dựng cơ chế chạy song song cho phép xử lý hàng trăm nghìn luồng 1 lúc. Giúp họ sắp xếp toàn bộ các trang website trên thế giới 1 cách nhanh chóng hơn
Tìm thông tin – Web Crawling, Lập chỉ mục – Indexing, Xếp hạng – Ranking...Là các giai đoạn tìm kiếm thông tin của Google
Google là cỗ máy tìm kiếm lớn nhất thế giới hiện nay, thuật toán và quy trình tìm kiếm dữ liệu website của nó đã được phát triển rất tối ưu. Trong bài viết này tôi sẽ mô tả quy trình tìm kiếm thông tin của Google. Bạn hiểu được quy trình này nó sẽ hỗ trợ rất nhiều cho bạn trong quá hình học và làm SEO.
Mattcutt đã có 1 video mô tả quá trình tìm kiếm của Google, các bạn có thể bật CC để xem bản dịch tiếng việt.
Những điều nên biết
Google bot tìm kiếm thông tin, tin tức mới và những trang web được thiết kế mới theo các nguồn:
Tưởng tượng Internet như 1 hệ thống xe buýt trong thành phố, mỗi điểm dừng là 1 tài liệu (bài viết, hình ảnh, file pdf,…). Nhiệm vụ của SE bot là phải đi qua hết các điểm này để thu thập thông tin. Giống như tuyến đường xe buýt, sẽ dẫn ta từ điểm A -> điểm B. Các Link liên kết giúp SE Bot đi từ webpage này sang webpage khác. Xem thêm bài viết: Cách SEO website lên top Google và ra đơn.

Làm sao website của bạn được Google crawl nếu như nó không có backlink nào cả? Để giải quyết vấn đề này Google phát hiện url mới thông qua việc submit sitemaps trên Google webmaster tool, hoặc HTTP request >> www.google.com/addurl.html.
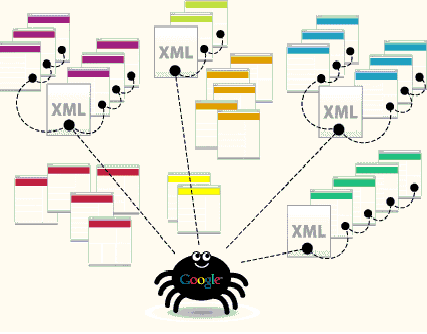
Quá trình tìm nội dung mới được Google thực hiện thường xuyên. Tuy nhiên spider không chạy theo các liên kết 1 cách ngẫu nhiên mà đi theo 1 thứ tự ưu tiên. SE bot sẽ quét dữ liệu trong các Danh bạ website lớn (dmoz, yahoo,…) – nơi có nhiều website, thường được update website mới -> Nhóm 1.
SE Bot tiếp tục tìm các link trong Nhóm 1 để tìm liên kết ngoài và đưa các link này -> nhóm 2. Toàn bộ các url này sẽ được quăng sang quá trình tiếp theo là Spam Filter để lọc các liên kết trùng lặp, hỏng. Trong quá trình này, nếu như những link đến bị lỗi (không truy cập được) nó sẽ được đưa lại quá trình Discovery Crawl. Tìm hiểu về thiet ke website
Giai đoạn 2: Lập chỉ mục – Indexing.
Các URL sạch có được sau quá trình Spam Filter sẽ được Google tung web cralwer vào để thu thập nội dung và xây dựng chỉ mục.
Đầu tiên Google phải thu thập nội dung trong website bằng cách sử dụng web crawler. Web Crawler tạo ra các HTTP request để truy cập vào website rồi bắt đầu thực hiện quá trình thu (retrieve) dữ liệu trên các trang đó. (Trong lúc này URL mới được nó phát hiện ra sẽ tiếp tục được đưa trở lại bước Discovery Crawl).
Sau khi có được dữ liệu phải làm bước tiếp theo là phân tích cú pháp để xác định nội dung của webpage.
Parsing – phân tích cú pháp: Parsing cho phép Google loại bỏ các từ phổ biến (và, thì,mà, là,…), loại bỏ các khoảng trống, con số để kết hợp các từ thành cụm từ lại thành có ý nghĩa.
Lọc 1 trang sách rất dễ nhưng với hàng tỷ trang web thì nó lọc và sắp xếp nó sẽ là khối lượng công việc khổng lồ. Google giải quyết bài toán này qua thư viện từ vựng, xây dựng cơ chế chạy song song cho phép xử lý hàng trăm nghìn luồng 1 lúc. Giúp họ sắp xếp toàn bộ các trang website trên thế giới 1 cách nhanh chóng hơn.
Sau khi 1 webpage qua bước Parsing nó sẽ được đánh dấu và cho vào 1 box riêng được mã hóa theo ID. Nó được phân loại theo nhiều cách khác nhau (khu vực, loại ngôn ngữ, chủ đề,…) để nhanh chóng nhất hiển thị ra khi có truy vấn tìm kiếm liên quan đến nó (từ khóa) – thông thường dưới 1s.
Cản trở lớn nhất cho Google trong Quá trình này đó là các lỗi html. Khi gặp lỗi Google không thể tự xử lý ngày mà phải dùng thuật toán để xác định lại. Điều này sẽ làm web của bạn sẽ bị chậm trễ khi index và đôi khi sẽ đưa ra kết quả sai.
Sau khi website của bạn đã được index trong data center của Google. Nó sẽ được đánh giá và xếp hạng để hiển thị ra ngoài trang kết quả tìm kiếm (SERP) thông qua thuật toán của Google.
Bảng dưới đây là các nhân tố cơ bản và có ảnh hưởng cao nhất tới thuật toán xếp hạng của máy tìm kiếm, được đánh giá theo thang điểm 5.
Dễ dàng bạn có thể nhận thấy các nhân tố Onpage được ứng dụng để hỗ trợ trong quá trình Parsing. Những từ khóa được làm nổi bật, xuất hiện trên những điểm nóng, có tần suất, mật độ xuất hiện cao. Giúp Google dễ dàng nhận biết được đâu là từ khóa chính, cụm từ chính để sắp xếp và phân loại website.
Nhân tố Off-Page Link anchor text contains keyword = 4.4/5
Các nhân tố Offpage liên quan rất nhiều đến việc xếp hạng website. Các Anchortext Link, Internal Link, Link velocity giúp Google tìm ra những trang đích có chất lượng và được đánh giá cao (có nhiều backlink chất lượng trỏ về). Xem thêm: 200 yếu tố quan trọng về từ khóa website xếp hạng google.
Chúng ta đã vừa đi qua các giai đoạn tìm kiếm và sắp xếp dữ liệu của Google, hi vọng bài viết này sẽ giúp các bạn căn bản hiểu được cách tìm kiếm của Google qua đó các bạn có thể dễ dàng giải thích các yếu tố ảnh hưởng đến thứ hạng của website trên Google.
* Tốc độ xây dựngliên kết – link velocity thể hiện tốc độ tăng trưởng của backlink trong một thời gian. Xem thêm bài viết: Dịch vụ seo website lên top google tìm kiếm thần tốc.
Hiện tại chúng tôi đang có chương trình khuyến mãi thiết kế web được thiết kế logo miễn phí + tên miền + hosting + hướng dẫn quảng cáo seo tổng thể marketing online miễn phí. Hãy liên hệ chúng tôi để biết thêm chi tiết.